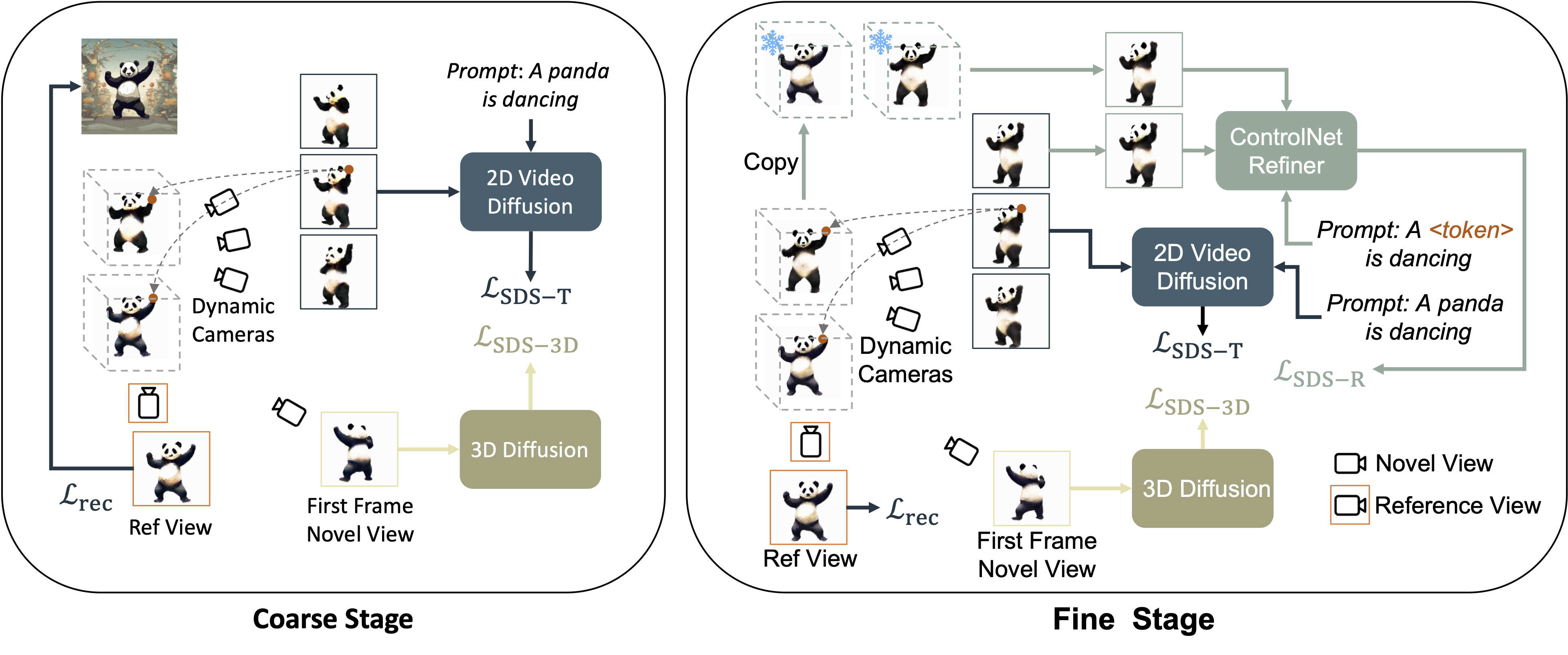
A panda is dancing

A Clownfish is swimming

A blue flag with Chelsea Football Club logo on it, attached to a flagpole,
waving with a smooth, gentle curve

A fox maneuvering a game controller with its paws

An astronaut, helmet in hand, rides a white horse

A monkey riding a bike

A space shuttle launching

A full-bodied tiger standing on its hind legs, confidently playing an acoustic guitar